什么是二维码
二维条码/二维码(2-dimensional bar code)是用某种特定的几何图形按一定规律在平面(二维方向上)分布的黑白相间的图形记录数据符号信息的;在代码编制上巧妙地利用构成计算机内部逻辑基础的“0”、“1”比特流的概念,使用若干个与二进制相对应的几何形体来表示文字数值信息,通过图象输入设备或光电扫描设备自动识读以实现信息自动处理。
常见技术标准有PDF417,QRCode,Code49Code16K,CodeOne等20余种。其中QRCode因为具有识读速度快、信息容量大、占用空间小、保密性强、可靠性高的优势,是目前使用最为广泛的一种二维码。
QRCode 正方形,只有两种颜色,在4个角落的其中3个,印有像“回”字的的小正方图案。QR码是属于开放式的标准,QR码的规格公开,而发明者的专利权益不会被执行。
QR码的“QR”源自“Quick Response”的缩写。
版本信息
QR码一共提供40种不同版本存储密度的结构,对应指示图的“版本信息”,Version 1为21×21模块(模块为QR码中的最小单元),Version 2为25x25像素大小,每增加一个版本,长宽各增加4个模块,最大的版本40为177×177模块。
计算公式是:(V-1)*4 + 21(V是版本号)。

容量
二维码的容量取决于它的版本和错误纠正级别,以及编码的数据类型。
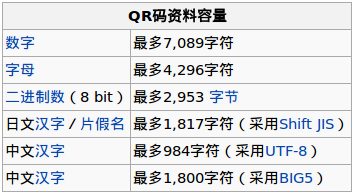
QR码最大数据容量(对于版本40):
容错率
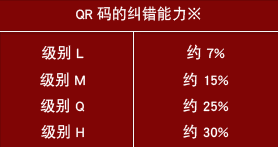
容错率也叫纠错率,就是指二维码图形如果有破损,仍然可以被机器读取内容,QR码最高可以到7%~30%面积破损仍可被读取。
例如:在二维码中间加上logo,建议选择H级容错率。
基本结构
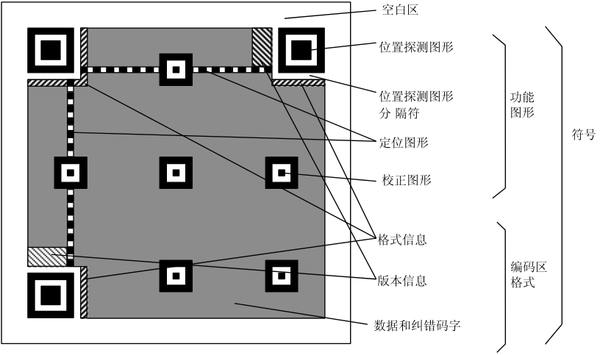
定位图案
- 位置探测图形:标记二维码整体的位置。
- 定位图形:标记二维码的数据内容的位置。
- 校正图形:大于 Version 2版本的二维码才有,根据版本信息来确定校正图形的数量和位置。主要用于QR码形状的矫正,尤其是当QR码印刷在不平坦的面上,或者拍照时候发生畸变等。
纠错码字
用于修正二维码损坏带来的错误。通过 Reed-Solomon error correction(里德-所罗门纠错算法)来实现的。
版本信息
二维码的规格,QR码符号共有40种规格的矩阵(一般为黑白色),从21×21(版本1),到177×177(版本40),每一版本符号比前一版本 每边增加4个模块。
格式信息
格式信息记录两个方面:纠错级别和用于符号的掩码图案。
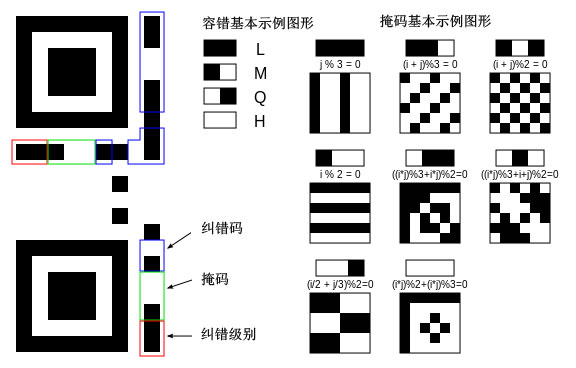
纠错级别:包含L、M、Q和H四个级别。L可纠正约7%错误、M级别可纠正约15%错误、Q级别可纠正约25%错误、H级别可纠正约30%错误。RS码原理比较复杂,整体基于“任意k个确定点可表示一个阶数至少为k-1的多项式”,实际上发送超过k个点,就算中间有一些错误,也能通过数学原理反推出最初的多项式,从而获得信息。并不是所有位置都可以缺损,像最明显的那三个角上的方框,直接影响初始定位。中间零散的部分是内容编码,可以容忍缺损。
掩码:用于分解数据区域中可能会混淆扫描仪的模式,例如大的空白区域或看起来像定位符的误导功能。掩模图案被定义在必要时重复以覆盖整个符号的网格上。对应于掩模暗区的模块被反转。使用BCH代码保护格式信息免受错误,每个QR符号中都包含两个完整的副本。
数据编码
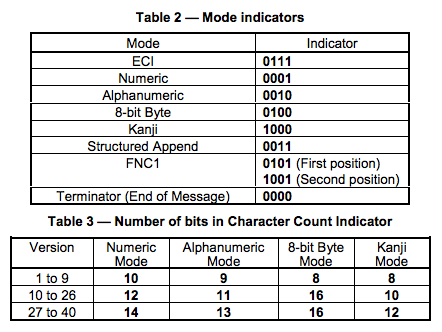
Numeric mode,数字编码,标识码为:0001。从 0 到9。如果需要编码的数字的个数不是 3 的倍数,那么,最后剩下的 1 或 2 位数会被转成 4 或 7bits,则其它的每 3 位数字会被编成 10,12,14bits,编成多长还要看二维码的尺寸( 表 Table 3 )。
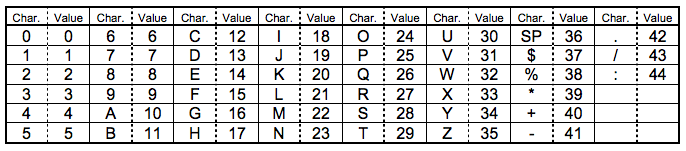
Alphanumeric mode,字符编码,标识码为:0010。包括 0-9,大写的A到Z(没有小写),以及符号$ % * + – . / : 包括空格。这些字符会映射成一个字符索引表。如下所示:(其中的 SP 是空格,Char 是字符,Value 是其索引值) 编码的过程是把字符两两分组,然后转成下表的 45 进制,然后转成 11bits 的二进制,如果最后有一个落单的,那就转成 6bits 的二进制。而编码模式和字符的个数需要根据不同的 Version 尺寸编成9, 11 或 13 个二进制( 表 Table 3 )。
Byte mode,字节编码,标识码为:0100。可以是0-255 的 ISO-8859-1 字符。有些二维码的扫描器可以自动检测是否是 UTF-8 的编码。
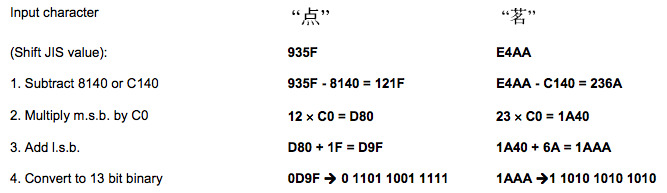
Kanji mode 这是日文编码,也是双字节编码,标识码为:1000。同样,也可以用于中文编码。日文和汉字的编码会减去一个值。如:在 0X8140 to 0X9FFC 中的字符会减去 8140,在 0XE040 到 0XEBBF 中的字符要减去 0XC140,然后把前两位拿出来乘以 0XC0,然后再加上后两位,最后转成 13bit 的编码。
- Extended Channel Interpretation (ECI) mode 主要用于特殊的字符集。并不是所有的扫描器都支持这种编码。
- Structured Append mode 用于混合编码,也就是说,这个二维码中包含了多种编码格式。
- FNC1 mode 这种编码方式主要是给一些特殊的工业或行业用的。比如 GS1 条形码之类的。
示例一:数字编码
在 Version 1 的尺寸下,纠错级别为H的情况下,编码: 01234567
1、 把上述数字分成三组: 012 345 67
2、把他们转成二进制: 012 转成 0000001100; 345 转成 0101011001; 67 转成 1000011。
3、把这三个二进制串起来: 0000001100 0101011001 1000011
4、把数字的个数转成二进制 (version 1-H 是 10 bits ): 8 个数字的二进制是 0000001000
5、把数字编码的标志 0001 和第 4 步的编码加到前面: 0001 0000001000 0000001100 0101011001 1000011
示例二:字符编码
在 Version 1 的尺寸下,纠错级别为H的情况下,编码: AC-42
1、从字符索引表中找到 AC-42 这五个字条的索引 (10,12,41,4,2)
2、两两分组: (10,12) (41,4) (2)
3、把每一组转成 11bits 的二进制:
(10,12) 1045+12 等于 462 转成 00111001110
(41,4) 4145+4 等于 1849 转成 11100111001
(2) 等于 2 转成 000010
4、把这些二进制连接起来:00111001110 11100111001 000010
5、把字符的个数转成二进制 (Version 1-H 为 9 bits ): 5 个字符,5 转成 000000101
6、在头上加上编码标识 0010 和第 5 步的个数编码: 0010 000000101 00111001110 11100111001 000010
结束符和补齐符
假如我们有个“HELLO WORLD”的字符串要编码,根据上面的示例二,我们可以得到下面的编码,1
2编码 字符数 HELLO WORLD的编码
0010 000001010 01100001011 01111000110 10001011100 10110111000 10011010100 001101
结束符
如果编码后的字符长度不足当前版本和纠错级别所存储的容量,则在后续补”0000”,如果容量已满则无需添加终止符。1
2编码 字符数 HELLO WORLD的编码 结束
0010 000001011 01100001011 01111000110 10001011100 10110111000 10011010100 001101 0000
按8bits重排
将编码按8bit一组,形成码字。如果尾部数据不足8bit,则在尾部充0。
上面一共有78个bits,所以,我们还要最后面加上2个0,然后按8个bits分好组:1
2编码 字符数 HELLO WORLD的编码 结束
0010 000001011 01100001011 01111000110 10001011100 10110111000 10011010100 001101 000000
补齐码(Padding Bytes)
最后,如果编码后的数据不足版本及纠错级别的最大容量,则在尾部补充 “11101100” 和”00010001”,直到全部填满。(这两个二进制转成十进制是236和17)关于每一个Version的每一种纠错级别的最大Bits限 制,可以参看QR Code Specification的第28页到32页的Table-7一表。
假设我们需要编码的是Version 1的Q纠错级,那么,其最大需要104个bits,而我们上面只有80个bits,所以,还需要24个bits,也就是需要3个Padding Bytes,我们就添加三个,于是得到下面的编码:1
2编码 字符数 HELLO WORLD的编码 结束符 补齐码
00100000 01011011 00001011 01111000 11010001 01110010 11011100 01001101 01000011 01000000 11101100 00010001 11101100
编码过程

数据编码:将数据字符转换为位流,每8位一个码字,整体构成一个数据的码字序列。其实知道这个数据码字序列就知道了二维码的数据内容。
对于字母、中文、日文等只是分组的方式、模式等内容有所区别,基本方法是一致的。二维码虽然比起一维条码具有更强大的信息记载能力,但也是有容量限制。
纠错编码:按需要将上面的码字序列分块,并根据纠错等级和分块的码字,产生纠错码字,并把纠错码字加入到数据码字序列后面,成为一个新的序列。
版本信息:生成版本信息放入相应区域内。版本7-40都包含了版本信息,没有版本信息的全为0。二维码上两个位置包含了版本信息,它们是冗余的。版本信息共18位,6X3的矩阵,其中6位时数据为,如版本号8,数据位的信息时 001000,后面的12位是纠错位。
创建二维码基本步骤
第一步:数据分析
二维码标准有多种编码模式:数字,字符,字节和日文等模式,每个模式使用不同的方法将文本转换为二进制数字,选择最优化的编码模式,尽可能用最短的一串二进制数字来编码数据。
第二步:数据编码
选择错误校正级别,确定数据的最小版本,增加模式指示符,增加字符计数指示符,使用所选模式进行编码,[分成8位码字和添加补齐码]。
第三步:生成纠错码
将数据码分组,执行多项式长除法,使用逐字节模100011101生成2的幂,生成多项式,生成纠错码,多次运算计算结果
第四步:最终编码
确定块数和纠错码字,数据交替排列,转为二进制,添加剩余位(补齐码)
第五步:矩阵中的模块放置
放置位置探测图形、定位图形、校正图形、数据块。保留版本信息、格式信息区域。
第六步:掩码图案
根据评价条件确定最佳掩码图案
第七步:格式和版本信息
最后放置版本信息、格式信息。
具体编码过程请移步【博客】你今天真好看
常见问题
如何导入QR码?
QR码系统可以分为两道工序,即QR码的制作和读取。QR码的制作是用“软件和打印机”来实现,读取时使用“扫描仪和应用程序”。用普通手机、智能手机、平板电脑各种移动设备读取QR码。
同样的内容做出来的二维码为什么都不一样?
这是由于,这些特定的几何图形按照一定规律,然后随机的分布在平面上。
什么样的情况或造成二维码无法读取?
码元变形。
码元是构成QR码的一个方形图块,大小取决于打印机打印头的点数。如下图:


例如,当打印头密度为300dpi时,在5点/码元的情况下码元大小为0.42mm/码元。构成一码元的点数越多,打印质量会越高,运用更稳定,可免受打印粗细、送纸速度不均匀、打印机轴变形、飞白等问题的影响。为了实现稳定的运用,DENSO WAVE INCORPORATED建议每个码元打印4点以上。

在确定QR码版本后,还要确定以码元(构成QR码的一个方形图块)要以多少mm打印,码元大小不同,QR码的实际尺寸也会有所不同。 码元越大,QR码扫描仪就越容易读取。
用图像处理工具等对QR码进行放大或缩小,会导致各个码元的变形。
虽然外观上与普通的QR码一样,但实际上却很难读取,甚至有时无法读取。

边缘有文字或图像
若在QR码的边缘印上文字或图像,则无法留出足够的边缘空白。
这样的二维码很难读取,甚至有时无法读取。

文字和图像等标记摆在二维码上
若在和QR码重叠的位置上印上文字或图像等标记,则明暗对比将变得模糊。
这样的二维码很难读取,甚至有时无法读取。

可将图像和声音作为数据写入吗?
一个QR码的容量最多不到3KB(版本40,纠错级别L)。而且,如果是用手机读取,手机所能读取的QR码因厂家和机型而有别,数据量一般为271个字节(版本10,纠错级别L)。可以理解为,通过手机读取QR码时,无法容纳图像和声音。
实际应用
微信的扫码登录实现原理
网页版微信刚推出时,无数人被它的登录方式惊艳了一下,不需要输入用户名密码,打开手机微信扫一扫,便自动登录。从原理上讲,二维码只能是一段文本的编码,如何用它实现快捷登录的呢?
打开网页版微信,可以看到如下的页面:
微信扫码界面
如果你用我查查、支付宝、新浪微博等软件扫码二维码,你会发现此二维码解析出来是如下的网址:
1 | https://login.weixin.qq.com/l/obsbQ-Dzag== |
接下来详细介绍一下扫码登录具体的每个步骤:

扫码登录完整流程
①:用户 A 访问微信网页版,微信服务器为这个会话生成一个全局唯一的 ID,上面的 URL 中 obsbQ-Dzag== 就是这个 ID,此时系统并不知道访问者是谁。
②:用户A打开自己的手机微信并扫描这个二维码,并提示用户是否确认登录。
③:手机上的微信是登录状态,用户点击确认登录后,手机上的微信客户端将微信账号和这个扫描得到的 ID 一起提交到服务器
④:服务器将这个 ID 和用户 A 的微信号绑定在一起,并通知网页版微信,这个 ID 对应的微信号为用户 A,网页版微信加载用户 A 的微信信息,至此,扫码登录全部流程完成